By
By 
Table of Contents
What is Fault Tolerance?
Fault tolerance refers to the capability of a system or component to maintain its functionality and performance, even in the presence of errors, faults, or failures.
Fault tolerance is a critical aspect of system design that aims to minimize the impact of failures and ensure the uninterrupted operation of the system. Different methods and strategies can be used to detect failures, isolate, and recover from faults. The system maintains its normal functioning even when the component fails or resource experiences disruptions.
Let’s check the 7 techniques of the fault tolerance system
7 Best Techniques of Fault Tolerance System
In distributed systems, fault tolerance is essential for ensuring that the system continues to function properly despite node failures, network disruptions, or other types of failures. To achieve fault tolerance, various techniques are employed. Here are seven of the best techniques used for achieving fault tolerance:
- Redundancy: Redundancy is a fundamental technique in fault tolerance. It involves duplicating critical components or resources in the system. By having multiple redundant components, such as servers or storage devices, failures can be mitigated, and the workload can be seamlessly transferred to backup components.
- Error Detection: This technique involves implementing methods to identify errors during data transmission, processing, or storage. It can involve parity checks, checksums, or cyclic redundancy checks. Early detection of errors allows for quick resolution and ensures the accuracy and reliability of the system.
- Failover and Failback: Failover is the process of automatically switching to a redundant or backup component when a failure is detected. Failover solutions ensure uninterrupted service and minimize downtime. Failback, on the other hand, is the process of returning to the primary component once it has been restored. Together, failover and failback techniques provide continuous operation and recovery from failures.
- Replication: Replication involves creating and maintaining multiple copies of critical data or resources across different locations or systems. This technique ensures that if one copy becomes inaccessible or corrupted, there are other copies available for use. Replication can be done at various levels, such as data replication, application replication, or system replication, depending on the specific requirements of the system.
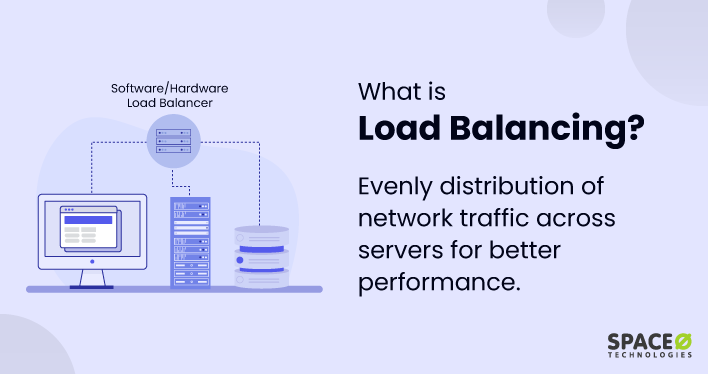
- Load Balancing: Load balancing is a technique that distributes the workload across multiple resources to ensure optimal resource utilization and prevent any single component from becoming overloaded. By evenly distributing the traffic, load balancing improves performance, scalability, and fault tolerance. It can be achieved through various algorithms, such as round-robin, least connection, or weighted distribution.
- Monitoring and Recovery: Fault-tolerant hardware systems employ monitoring mechanisms to continuously monitor the health and performance of components. If a failure or abnormal condition is detected, recovery mechanisms are initiated to restore the system to a functional state. This may involve restarting failed components, restoring data from backups, or reallocating resources to ensure continued operation.
- Multi-version Technique: The multi-version technique involves developing multiple independent versions of a computer system or component, each designed by a different team or using different algorithms. These versions run in parallel, and their outputs are compared to determine the correct result. This approach increases fault tolerance by reducing the likelihood that all versions will fail simultaneously or produce the same incorrect output.
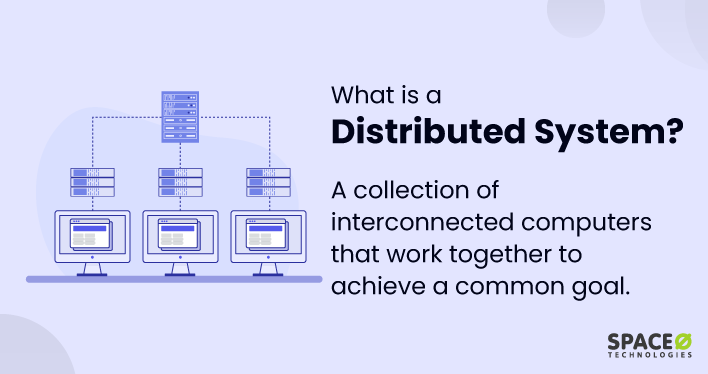
These techniques work in synergy with distributed systems to achieve fault tolerance and ensure the reliability and availability of systems. If you are not familiar with distributed systems, here is a brief definition of distributed systems. Reading this article, you will have an understanding of its importance and types.
By implementing these techniques of fault tolerance, organizations can minimize downtime and minimize service interruption even if the components fail.
7 Benefits of Implementing Fault Tolerance System
Here are the 7 key benefits of implementing a fault-tolerant system:
- Increases Reliability: Fault tolerance enhances the reliability of computer systems by mitigating the impact of failures. It reduces the likelihood of system crashes, downtime, and service disruptions. By incorporating components and a working backup system, fault tolerance ensures that systems including the operating system can continue to function even when individual components fail.
- Improves Availability: Fault-tolerant design provides continuous availability of services. By incorporating techniques like failover, replication, and load balancing, fault tolerance ensures that services remain accessible to users even in the event of failures. This minimizes service interruptions and enhances user satisfaction.
- Minimizes Downtime: Fault-tolerant system reduces downtime by quickly detecting failures and initiating recovery mechanisms. With redundant components and failover capabilities, systems automatically switch to backup resources, minimizing the impact of failures and maintaining uninterrupted operations. This leads to improved productivity and reduced financial losses associated with downtime.
- Protects Data: By using fault-tolerant computing techniques like replication and backup systems, fault-tolerant software systems ensure that data is stored in multiple locations and can be recovered in case of data corruption or data loss. This safeguards against data breaches, accidental deletions, or hardware failures, ensuring data integrity and business continuity.
- Provides Scalability and Flexibility: Fault-tolerant systems are designed to handle increased workloads and accommodate growing demands. By incorporating load-balancing solutions and distributed architectures, fault tolerance allows systems to scale horizontally by adding additional resources or servers as needed. This ensures that the system can adapt to changing demands and maintain optimal performance.
- Enhances Performance: Fault tolerance improves system performance by distributing workloads across multiple resources and preventing any single component from becoming a performance bottleneck. Load balancing techniques ensure efficient resource utilization, reducing response times and enhancing overall system performance.
- Business Continuity: Fault tolerance is a key component of a comprehensive business continuity strategy. By providing continuous operation and mitigating the impact of failures, fault-tolerant systems enable organizations to maintain critical services and operations during unexpected events or disasters. This ensures that essential functions can continue to operate, minimizing the impact on business operations and reputation.
By implementing fault-tolerant measures, you can ensure the reliability and resilience of their systems, providing uninterrupted services to users and protecting critical data and operations.
5 Examples of Fault-Tolerant Systems
- Redundant Array of Independent Disks (RAID): RAID technology provides fault tolerance by combining multiple physical disks into a single logical unit. It offers data redundancy and improved performance, allowing the failover system to continue operating even if one or more disks fail.
- High Availability Clusters: High availability clusters involve grouping multiple servers together to form a cluster. If an identical server fails, the workload is automatically redistributed to the remaining servers in the cluster, ensuring uninterrupted service availability.
- Uninterruptible Power Supply (UPS): UPS systems provide backup power in the event of a power outage. They ensure that critical systems and devices have a continuous power supply, allowing them to function without interruption until the main power source is restored.
- Distributed Database Replication: Fault tolerance relies on replication to achieve distributed databases. Data is replicated across multiple network nodes or servers, ensuring that if one node fails, the data is still accessible from other nodes, maintaining data availability and integrity.
- Virtualization and Containerization: Virtualization and containerization technologies provide fault tolerance by isolating mission-critical applications or services in virtualized or containerized environments. If one virtual machine or container fails, the other instances can continue running, minimizing the impact on overall system performance.
Fault tolerance is an essential concept in system design and plays a critical role in ensuring the reliability, availability, and performance of systems. By understanding and implementing fault tolerance principles, organizations can build mission-critical systems that can withstand failures and ensure the continuous delivery of services.